
The Merge series (part 1): Performance
Welcome to the Merge series! This is part 1 of a 3 part blog post series, on some of the most interesting observations we were able to surface from our data, around The Merge. In this post, we dive deep in validator performance, as evidenced on-chain in the 90 days around The Merge.
Key takeaways
Overall network performance is high–albeit trending marginally down, with misses in terms of attesting to the correct head of the chain contributing to performance degradation the most.
Home stakers appear to have had a harder time than larger operations maintaining performance during the Bellatrix and Merge upgrades, as well as the whole post-Merge period.
Running mev-boost does not appear to correlate with validators missing block proposals, and thus so far appears to not affect overall performance.
How we measure operator performance at Rated
In order to better gauge the actual performance of validators outside of simply looking at the rewards they received, we have crafted the “Rated validator effectiveness” metric. This metric considers how well a validator fulfills both their attestation and proposer duties, assigning to each of the component parts considering how important they are to the network and to each validator.
You can take a deeper dive into the Effectiveness Rating methodology, as well as into how it is slated to change moving forward, via our documentation. For a deeper dive into why we think the Effectiveness Rating is a better descriptor of performance, we recommend you revisit this talk from EthCC 2022.
Overall network performance around the Merge
For the most part, network-wide validator effectiveness (and thereby network health), in an absolute sense, has been consistently high pre- and post- Merge, sitting at over 95%.
There have been two instances where effectiveness has dropped below 95% to 93% (The Merge) and 90% (Bellatrix Upgrade) levels, which historically as far as Beacon Chain Mainnet goes, are tail-type events; this type of performance has been observed less than 0.1% of the time since Beacon Chain launch.
In both cases the network recovered pretty quickly after the upgrades were completed.

Figure 1: Overall network validator effectiveness around the Merge
It is worth noting, however, that since the beginning of August 2022, overall validator effectiveness is in a mildly downward trend. The observation could be associated with the fact that The Merge has increased the amount of duties that validators need to perform, and with it the amount of resources a validator requires and the dependencies that a validator takes on.
Proposer effectiveness
With more jobs that need to be done we suspect that overall network latency increases, which amounts to both more missed blocks as well as less correct source, target and head attestations (see section “attester effectiveness” in our documentation for a reference as to why that might be the case).
Indeed, when looking at proposer effectiveness (you can also think of this as an inverse missed proposal rate) around the Merge dropped from a near perfect 99.98% to 99.36%, with a clear cut-off date on the trend change on the day of the Merge.

Figure 2: Proposer effectiveness around the Merge
This corresponds to 2,019 validators who have missed proposing a block since the Merge. Out of those we have mapped 51% of them as running mev-boost (i.e. outsourcing block production duties to specialized entities called builders). Given that we have seen mev-boost adoption grow from 25% in the first week post-Merge, to over 80% at present, but at the same time are observing proposal miss rates stay relatively flat and in fact stabilizing since the Merge, we think it is highly unlikely that the introduction of mev-boost is the culprit for the increase in the missed-block rate.
Attester effectiveness
Now breaking down the attester effectiveness component of overall validator effectiveness, we have observed that head vote accuracy has been significantly lower than target and source accuracy, while exhibiting more than 5x the variance, and is trending negatively on average 2x as sharply, as its counterparts do, post-Merge.
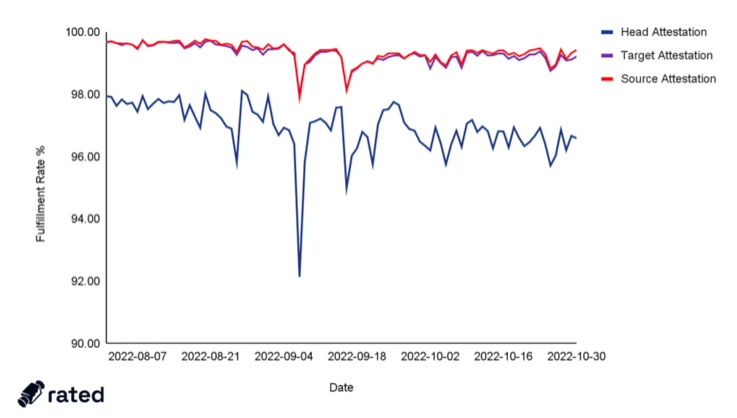
Figure 3: The components of attestation effectiveness across all network validators around the Merge
As a refresher, the head vote is the field a validator is called to attest to that relates to what the current tip of the chain is. A significantly divergent head attestation accuracy then implies that a non-trivial (albeit still small) chunk of the validator mass on Mainnet have been having trouble identifying the correct head of the chain.
To understand why this is happening, we looked at the different correlates around the observation. There are a couple points of not here; first, it looks as if the bottom 15% of the Ethereum Mainnet validator mass in terms of head vote accuracy, is contributing significantly more to the whole than other cohorts.

Figure 4: Head attestation accuracy of the bottom 15% vs the rest of the network
This bottom 15% is representative of a sample of ~68k validators. In that sample, we found that there’s a divergent over-representation of Lighthouse as the consensus client choice (34%), which compared to the 24% overall network penetration of Lighthouse, might point to something being amiss with the client itself–although we would steer clear of attributing a causal relationship.

Figure 5: Client distribution of the bottom 15% of network's validators in terms of head attestation accuracy vs the whole network's client distribution
Validator performance by cohort
The other very interesting direction we thought we could take, is look at the performance of validator operators not in terms of who did better than who on a nominal basis, but rather segregated by cohort–and slicing these cohorts according to the size of the operation. In particular the impetus was to see how home stakers as a group fared compared to professional operators.
While this approach will always have imperfections, we took all the appropriate steps to make sure that we remove error from the grouping methodology.
The grouping methodology
The way we conceptualise groupings in our classification system, separates entities (that is groups of pubkeys bound together by agency) into the following categories, presented in hierarchical order; (i) parent entities, (ii) entities, (iii) deposit addresses, and (iv) pubkeys.
The lowest order to grouping by commonality is the aggregation of pubkeys by deposit addresses. The next one up is grouping deposit addresses up to the entities that they are associated with; this slice normally encompasses node operator entities. The final leg up is grouping up operators into parent entities, which are normally pools; these could be off-chain registries like Coinbase or on-chain like Lido or Rocketpool.
For the purpose of this cohort analysis we’ve tweaked the hierarchy a bit, such that it follows an entity > parent entity > deposit address order of aggregation, so that we get as close to the operation frame of reference, as possible.
The table below outlines how these cohorts were shaped:

Table 1: 5 different cohorts of network validators and their respective network stake shares
The cohort analysis
We ran the analysis by cohort, based off of the Rated Validator Effectiveness rating. What we found was quite interesting; it seems that while the all cohorts were performing similarly pre-Merge, post-Bellatrix and particularly post-Merge the deltas between them have widened significantly and remain so.
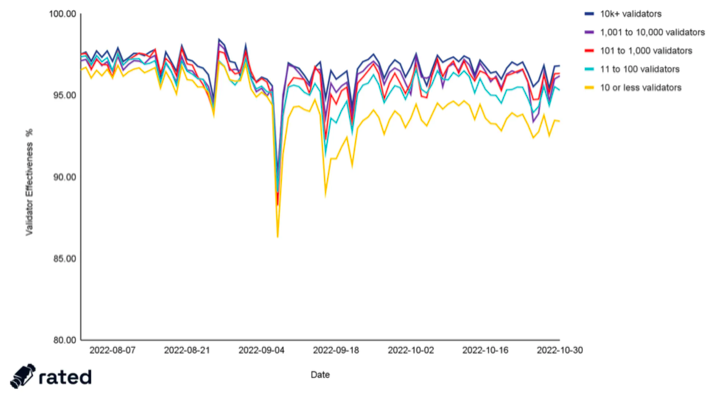
Figure 6: Aggregate validator effectiveness of each cohort around the Merge
Altogether, while the >1k keys cohorts have largely maintained their level of performance, all others have degraded post-Merge, with the delta of average performance pre- and post-Merge widening with every successive cohort slicing. We also have observed the variance delta increase between larger and smaller operators, post-Merge.

Figure 7: Boxplots of validator effectiveness by cohort in the pre- and post- Merge periods of the sample

Table 2: Validator effectiveness by cohort in the pre- and post- Merge periods of the sample
To illustrate the delta in performance widening, we plotted the two large cohorts against the smallest cohort in a time series. We found that in the more stable periods of the pre- and post-Merge parts of the 90 days sample, the difference in effectiveness between the two groups more than doubled. We also found that during the actual upgrades the performance difference widened the most, reaching ~6% and ~8% local maxima respectively, before normalizing.

Figure 8: Performance difference between chohorts of operators with 1,000+ keys and 10 or less keys associated with them
The trends we observed in the overall network analysis, as expected, persist in the cohort analysis, These performance differences have been the most apparent in the proper fulfillment of attestation duties, and in particular when it comes to attesting to the correct head of the chain.
Stay tuned for part 2 of our Merge series on Validator Rewards.